In order to handle large datasets our API supports Pagination. Pagination allows you to retrieve the subsets of data, making it easier to manage and process. It also has filtering and sorting capabilities to search the endpoints.
¶ Pagination Query parameters
Pagination is deactivated by default and must be specified in each API request. There are 4 available query parameters that you may use namely, offset, limit, next and previous.
limit (optional):
Description: It determines the number of records that will be retrieved.Data type: IntegerExample: limit=10Note: The default value if 50. The maximum value is 1000
offset (optional):
Description: It determines how many records will be skipped before being included in the returned results. It specifies the starting point from where the data should be fetched.Data type: IntegerExample: offset=50Note: if not provided, the default is 0
For example if there are a total of 100 records, by setting offset to 50 and limit to 20, we are returning a total of 20 records from the second set of records. It means that a total of 20 records will be returned from the second page of the API endpoint.
next (optional):
Description: Provides the URL to fetch the next page of the dataData type: String (URL)Example:https://goadmin.ifrc.org/api/v2/personnel/?limit=50&offset=150Note: The parameter is present only if the next page is available
previous (optional):
Description: Provides the URL to fetch the previous page of the dataData type: String (URL)Example:https://goadmin.ifrc.org/api/v2/personnel/?limit=50&offset=50Note: The parameter is present only if there is a previous page is available.
¶ Pagination best practices
It is very important to verify whether the correct number of records have been retrieved from the database. Once you have used the Pagination query parameters to retrieve all the records from the database, you no longer need to make additional API requests.
To determine if additional API requests are needed, you should compare the value of limit parameter with the total number of obtained records. If the number of records are less than the limit parameter's value, then no additional requests are required.
If the number of records is equal to the limit parameter's value, then you may need to send additional API requests. It is also important to check the value of the offset parameter. An offset value of 0 indicates that the data is fetched from the first first page.
If you see an empty array [] in the body of the response, it means that there are no records for that request and you don't need to send additional API request.
¶ Example Usage
Request
curl -X 'GET' \
'https://goadmin.ifrc.org/api/v2/event/?imit=100&offset=0&l®ions__in=2&countries__in=84' \
-H 'accept: application/json'
Response
Response body
Download
{
"count": 78,
"next": null,
"previous": null,
"results": [
{
"dtype": {
"id": 4,
"name": "Cyclone",
"summary": "",
"translation_module_original_language": "en"
},
"countries": [
{
"iso": "IN",
"iso3": "IND",
"id": 84,
"record_type": 1,
"record_type_display": "Country",
"region": 2,
"independent": true,
"is_deprecated": false,
"fdrs": "DIN001",
"average_household_size": null,
"society_name": "Indian Red Cross Society",
"name": "India",
"translation_module_original_language": "en"
}
(...)
In the example, the API response we fetch the data from the Event API endpoint. The data is obtained based on the previous and next parameters. The countries__in and regions__in have been used to filter the data. limit==100 means that we are obtaining 100 records and offset=0 means that data is fetched from the first till the last page. In the response we obtain only 78 records because these records have been filtered out for Nepal using the countries__in and regions__in parameters.
¶ Pagination in Power BI/ Excel
Whenever you are using PowerBI or any other service by default it will be accessing and showing you the data from the first page of the API endpoint which contains 50 records by default. If you want to access all the data coming stored on any particular API endpoint, this section shows you how you can do that in PowerBI/ Power Querry.
Using the steps below you can retrieve the data from the API using pagination along with authorization token and parameters. In this example we will be accessing the Events data and will use regions__in and countries__in as parameters.
- In order to access the data from all the API pages for a particular API end point, instead of selecting Get Data from the top ribbon, select Transform data. This will open the Power query editor.
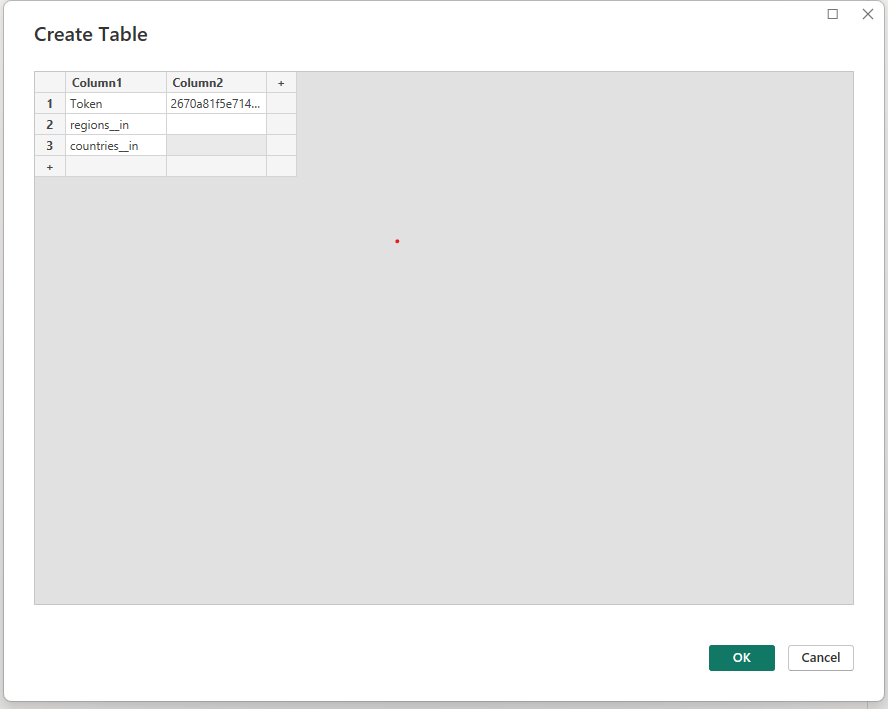
- We first define a Parameters table which will contain the Authorization token,
regions__inandcountries__inparameters that will be used in querying the data from the events API endpoint. - Click on Enter Data under the Home ribbon. This will open a window where a table can be created by entering the Authorization token and the two other parameters.
- Lets leave the
regions__inandcountries__inparameters as blank. - Upon clicking OK, a new query will be created under the Queries window. Lets rename this query to Parameters. The query can be renamed by changing its name under the Properties situated on the right side of the editor window.
- Under the Home ribbon, from New Source, select Blank Query. Click on Advance editor, this will open the advance query editing dialog box. Advance editor uses the m language to edit the query. In the advance editor window, paste the following code:
let
// Get the parameter values
ParametersTable = Parameters,
Token = Table.SelectRows(ParametersTable, each [Column1] = "Token"){0}[Column2],
region = Table.SelectRows(ParametersTable, each [Column1] = "regions__in"){0}[Column2],
country = Table.SelectRows(ParametersTable, each [Column1] = "countries__in"){0}[Column2],
BaseUrl = "https://goadmin.ifrc.org",
RelativePath = "api/v2/event/",
PageSize = 50, // Number of items per page
// Construct the query based on parameter values
queryOptions =
[
countries__in = if country <> null then Text.From(country) else "",
regions__in = if region <> null then Text.From(region) else "",
limit = Text.From(PageSize),
offset = "0" // Set initial offset to 0 as a string
],
GetPage = (offset) =>
let
Url = BaseUrl,
Headers = if Token <> null then [#"Accept-Language"="en", #"Authorization"="Token " & Token] else [#"Accept-Language"="en"],
Response = Json.Document(Web.Contents(Url, [Headers=Headers, RelativePath = RelativePath, Query=queryOptions & [offset = Text.From(offset)]])),
Results = Response[results]
in
Results,
CombineAllPages = List.Generate(
() => [Offset = 0],
each let page = GetPage([Offset]) in page <> null and List.Count(page) > 0,
each [Offset = [Offset] + PageSize],
each GetPage([Offset])
),
#"Converted to Table" = Table.FromList(CombineAllPages, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandListColumn(#"Converted to Table", "Column1")
in
#"Expanded Column1"
- In the code above the Token, region and country variables derive their values from the Parameters table that was constructed in the previous steps.
- We also define the BaseUrl which tells the PowerBI to connect with the Events API endpoint on the GO server. To see the full details of the API endpoints visit
https://goadmin.ifrc.org/api-docs/swagger-ui/. - The number of records on every page are stored in the PageSize variable. Since each API page contains 50 records, set this variable to 50.
- The
queryOptionsvariable in this code is constructing the filter query parameter that will be appended to the API URL to filter the results. It is checking if theregionandcountryparameter values are null or not, and constructing different filter values based on that. The filter allows the query to the API to be customized based on the input parameters, to filter the results returned from the API. - The
GetPagefunction is responsible for constructing the full API URL for a specific page, making the API request based on the parameters used, parsing the response and returning just the array of results for that page. - The
CombineAllPagesfunction is responsible for looping through all available pages of results from the API and combining them into a single list. It loops through all the available pages by incrementing the page counter. It callsGetPageto fetch each API page, stops when theGetPagereturn 0 and accumulates all the results into a single list. - After the code has been pasted in the advance editor window, click on done. A series of steps will be added in the APPLIED STEPS on the right side of the query editor window.
- Since the Events API endpoint consists of 102 pages at present, we can see 102 rows in the data obtained. Having a list with record does not tell us much. Converting it to a table will make it easier to read so click on the Convert to Table in the Transform section of the ribbon at the top of the window. In the window that pops up, select None and Show as errors for the two options.
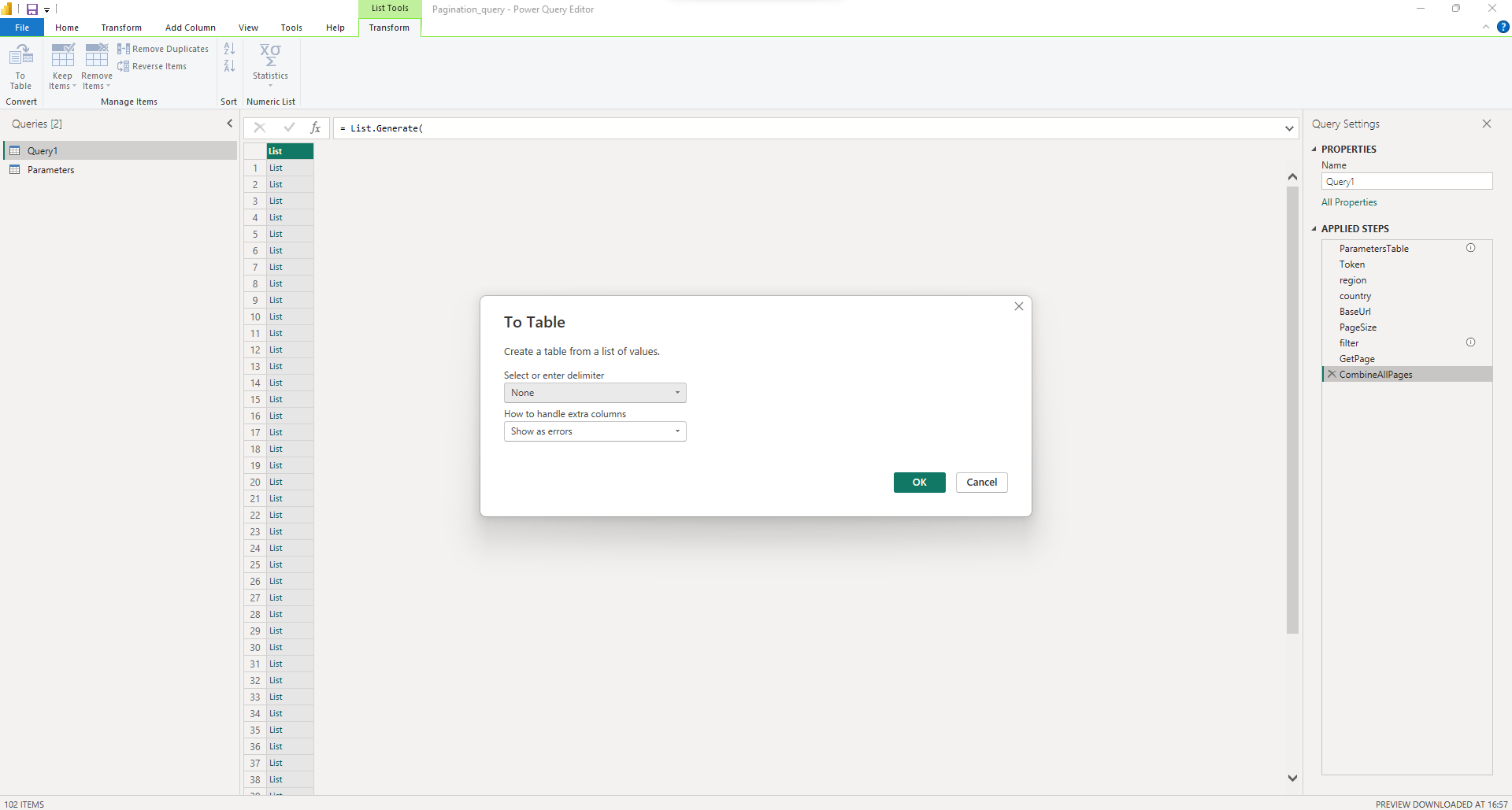
- Right now our table has an index column and Column1 which is just a place holder for the data for that particular result. Next to the name of the column click on the button and select Expand to new rows. Now we can see all the records obtained from every page. Again click on the button next to the name of the column and we are able to see what data this query is providing us. We select the fields which we would like to see in our data and click ok.
Note: We can also specify the values of
regions__inandcountries__inparameters in the Parameters Table. This will further filter the data from all the API pages. For example if we specify theregions__in = 2andcountries__in = 84, then we will obtain 77 records.
¶ Pagination in Python
Here we show how can you retrieve data from the GO API using python. We will be retrieving the data from all the pages of the Event API endpoint and will also filter the data using the regions__in and countries__in parameters. First we import the necessary python packages that will be used to retrieve the data.
import requests
import os
from concurrent.futures import ThreadPoolExecutor
from functools import partial
import pandas as pd
The following packages have been imported :
requests: Used for sending HTTP requests and handling responses, commonly used for web scraping, API interaction, and downloading web content.concurrent.futures.ThreadPoolExecutor: Part of theconcurrent.futuresmodule, used for managing a pool of worker threads to execute functions concurrently.functools.partial: Allows you to create partial functions by fixing a certain number of arguments of a function and generating a new function.pandas: Provides data structures and data analysis tools for working with structured data.
Next we specify the API URL and Authorization token. The Page_limit is set to 50 because each page contains 50 records.
api_url = "https://goadmin.ifrc.org/api/v2/event/"
auth_token = "Your Authorization token"
page_limit = 50 Next we define a function called fetchpage which will be used to retrieve the data from the API pages. In this function we also specify our filtering parameters namely regions__in and countries__in which with the help of which we will be filtering out data. We also specify a header dictionary in which we provide the authorization token.
def fetch_page(page_num, limit=50, offset=0, regions__in=None, countries__in=None):
params = {"limit": limit, "offset": offset + limit * (page_num - 1)}
if regions__in or countries__in:
params["regions__in"] = regions__in
params["countries__in"] = countries__in
headers = {"Authorization": f"Bearer {auth_token}"}
response = requests.get(f"{api_url}", params=params, headers=headers)
return response.json()
Note: The data from the GO API can be requested in 4 supported languages namely English, French, Arabic and Spanish. If you want the API response in the any of the 4 languages, you can specify another header in the fetch_page function as shown below:
headers = { "Authorization": f"Bearer {auth_token}", "Accept-Language": "two letter language code" # Add the Accept-Language header with the desired language }
Since the API endpoint contains over 100 pages, we will be parallelizing the task. We first calculate the total number of API pages and will be utilizing the concurrent.futures module to parallelize the execution of a function called fetch_page across multiple threads.
max_workers = multiprocessing.cpu_count()
response = requests.get(api_url)
if response.status_code == 200:
total_records = response.json()["count"]
else:
print(f"Failed to fetch total records count. Status code: {response.status_code}")
total_pages = (total_records + page_limit - 1) // page_limit
print("total_pages: ", total_pages, "\ntotal cpu count: ", max_workers)
with ThreadPoolExecutor(max_workers=max_workers * 4) as executor:
page_nums = range(1, total_pages + 1)
partial_fetch_page = partial(fetch_page, limit=50, offset=0)
results = executor.map(
partial_fetch_page, page_nums
) # regions__in = "2", countries__in = "84"
final_results = []
for result in results:
item = result
final_results.extend(item["results"])
The partial function is used to fix some arguments of fetch_page while leaving others as parameters to be filled later. In this case, it sets default values for limit, offset, regions__in, and countries__in.
executor.mapmethod is used to apply thepartial_fetch_pagefunction to each page number inpage_nums. This means that the fetch_page function will be executed concurrently for each page number using the thread pool. The map function returns an iterator of results.
In summary, the code is using a thread pool to fetch data from multiple pages concurrently, and it collects the results into a list called final_results.
The code below converts the retrieved data in to pandas data frame. The expand is a function which has been used to flatten out the data in the dtype, countries and appeals JSON objects. The same function can also be used to expand/ flatten out other JSON objects in the data and later the user can filter out the columns and prepare the data for visualization. Lastly the data has been exhorted to a csv format.
df = pd.DataFrame(final_results)
def expand(data_frame, column=str):
result = data_frame.explode(column)
result = result.reset_index(drop=True)
return result
# expandingh the countries and appeals columns as
# the data is stored as list
result = expand(df, "countries")
result = expand(result, "appeals")
# Get the index of the columns "countries" , "dtype" and "appeals"
countries_index = result.columns.get_loc("countries")
appeals_index = result.columns.get_loc("appeals")
dtype_index = result.columns.get_loc("dtype")
# Concatenate and expand columns
df_expanded = pd.concat(
[
pd.json_normalize(result["dtype"], sep="_").add_prefix("dtype."),
pd.json_normalize(result["countries"], sep="_").add_prefix("countries."),
result.iloc[
:, countries_index + 1 : appeals_index
], # columns between "countries" and "appeals"
pd.json_normalize(result["appeals"], sep="_").add_prefix("appeals."),
result.iloc[:, appeals_index + 1 :], # columns after "appeals"
],
axis=1,
)
#storing the data in csv format
df_expanded.to_csv("your/path/to/save/the/file/df_expanded.csv")