In this Sample API query we will be accessing the data from the Projects API endpoint using PowerBI/ Excel and python and visualize the number of projects per sector in Nepal.
¶ API Endpoint
The API endpoint can be accessed by building a URL query in PowerBI or Microsoft Excel. In this example we will be accessing the data from the Projects API endpoint and parameter Country to Nepal. In order to access Projects in a specific country, you need to write the associated 3 letter ISO3 code (specifically, the Alpha-3 code).
So our URL for this specific search would look like this:
https://goadmin.ifrc.org/api/v2/project/?country=NPL
- Here
https://goadmin.ifrc.org/api/tells PowerBI (or any other service/tool referencing the API) to connect with the GO server. All of your API calls to GO will start with this as a base URL. - The
v2/project/refers to the latest version of the API. There are multiple data tables within the database and project tells GO to search for the table that stores projects data ( as opposed to , say appeals, or the deployments. See https://goadmin.ifrc.org/api-docs/swagger-ui/ to see a full list of the available API endpoints. - The
country=NPLis the parameter that has been used to filter the projects in Nepal.
Since the data is coming from a paginated API, we will be utilizing the method used on the Pagination page along with the authorization token.
¶ Using PowerBI/ Excel
- Select Transform data from the top ribbon to open the Power query editor.
- We define a parameters table which contains the Authorization token and country parameters that will be used in querying the data. We can construct a table by clicking on the Enter Data option under the Home ribbon and write the authorization code and 3 letter ISO3 code NPL for Nepal.
- Click OK and a new query will be generated under the Queries window. Lets rename this query to Parameters.
- Under the Home ribbon, from New Source, select Blank Query. Click on Advance editor, this will open the advance query editing dialog box. Advance editor uses the m language to edit the query. In the advance editor window, paste the following code:
let
// Get the parameter values
ParametersTable = Parameters,
Token = Table.SelectRows(ParametersTable, each [Column1] = "Token"){0}[Column2],
country = Table.SelectRows(ParametersTable, each [Column1] = "country_iso3"){0}[Column2],
BaseUrl = "https://goadmin.ifrc.org/api/v2/project/",
PageSize = 50, // Number of items per page
// Construct the query based on parameter values
filter =
if country <> null then
"?country=" & Text.From(country)
else
"?" ,
GetPage = (page) =>
let
Url = BaseUrl & filter & "&limit=" & Text.From(PageSize) & "&offset=" & Text.From(page * PageSize),
Headers = if Token <> null then [#"Accept-Language"="en", #"Authorization"="Bearer " & Token] else [#"Accept-Language"="en"],
Response = Json.Document(Web.Contents(Url, [Headers=Headers])),
Results = Response[results]
in
Results,
CombineAllPages = List.Generate(
() => [Page = 0],
each List.Count(GetPage([Page])) > 0,
each [Page = [Page] + 1],
each GetPage([Page])
),
#"Converted to Table" = Table.FromList(CombineAllPages, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandListColumn(#"Converted to Table", "Column1")
in
#"Expanded Column1"
- In the code above the Token and country variables derive their values from the Parameters table that was constructed in the previous steps.
- The number of records on every page are stored in the PageSize variable. Since each API page contains 50 records, set this variable to 50.
- The filter variable in this code is constructing the filter query parameter that will be appended to the API URL to filter the results. It is checking if the country parameter values are null or not, and constructing different filter values based on that. The filter allows the query to the API to be customized based on the input parameters, to filter the results returned from the API.
- The GetPage function is responsible for constructing the full API URL for a specific page, making the API request based on the parameters used, parsing the response and returning just the array of results for that page.
- The CombineAllPages function is responsible for looping through all available pages of results from the API and combining them into a single list. It loops through all the availabl;e pages by incrementing the page counter. It calls GetPage to fetch each API page, stops when the GetPage return 0 and accumulates all the results into a single list.
- After the code has been pasted in the advance editor window, click on done. A series of steps will be added in the APPLIED STEPS on the right side of the query editor window.
- After that we need to expand the data and selecting the necessary features/ columns. we can do this by clicking on the icon next to the name of the column.
- At the moment we will select only a few columns namely: primary_sector_display, secondary_sectors_display, operation_type_display and programme_type_display.
- Now we’re able to see what data this query is actually providing us! We’re ready to start building our visuals, so click Close and Apply at the top of your Power Query Editor window.
¶ Visualization in Power BI
There are three icons that appear on the far left of the screen namely:
- Report Icon: The "Report" icon is where you create and design interactive visual reports. In this section, you can build visualizations, charts, and dashboards to present your data in a meaningful way for analysis and sharing with others.
- Data Icon: The "Data" icon allows you to access and transform your data before creating visualizations. Here, you can connect to various data sources, perform data modeling, cleansing, and shaping tasks to prepare your data for analysis in Power BI.
- Model Icon: The "Model" icon represents the data modeling aspect of Power BI. In this section, you can define relationships between tables, create calculated columns, and build data models that serve as the foundation for creating meaningful visualizations and reports.
- To build visualizations select the Report icon. On the right side of the window you will see three sections namely: Filters, Visualizations and Fields. If they are collapsed, you can use the arrow to expand them. For this section we will be using the bar charts for visualizing the projects distributed in primary sectors in Nepal.
- After clicking on the appropriate chart type, a blank place holder will appear in the preview pane. To show data on the chart, you will need to drag the relevant fields from the right pane in to the X-axis and Y-axis.
- From the data tab select the table which has the data of the projects and scroll to find the field primary_sector_display. Drag it to both the X and Y axis. Power BI is smart enough to understand what we are doing so it will automatically count the frequency of projects in different sectors. it counts the frequency of each unique value that appears and generates the bar chart.
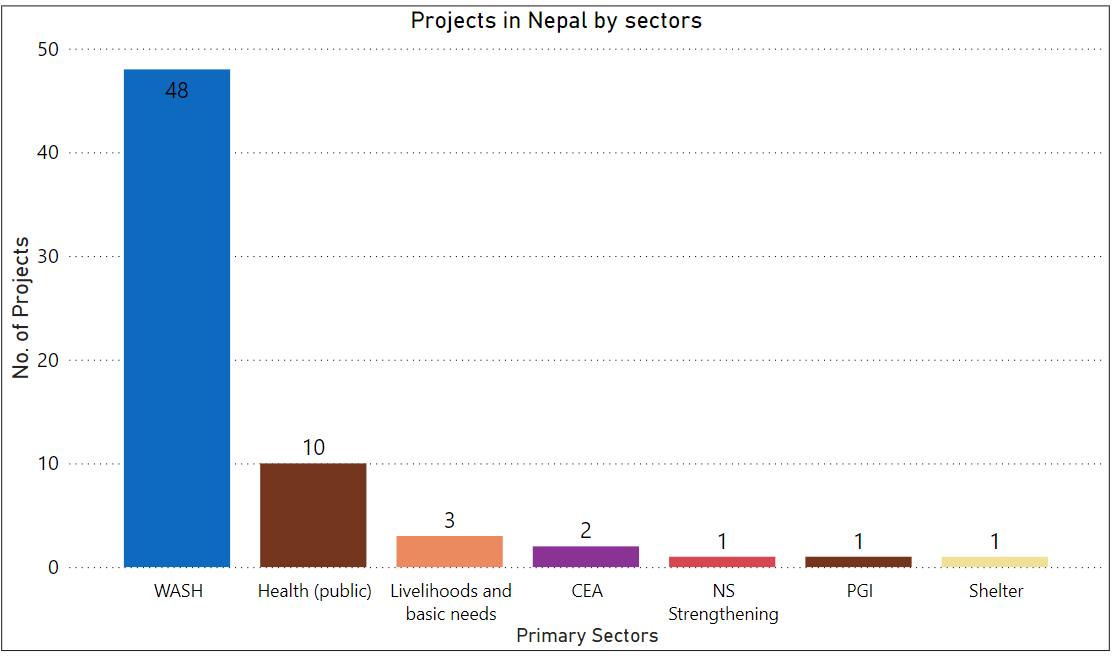
- The Bar chart can be customized, for example by changing the name and sizes of the axis and the title. The following bar chart would be obtained if the above steps are followed:
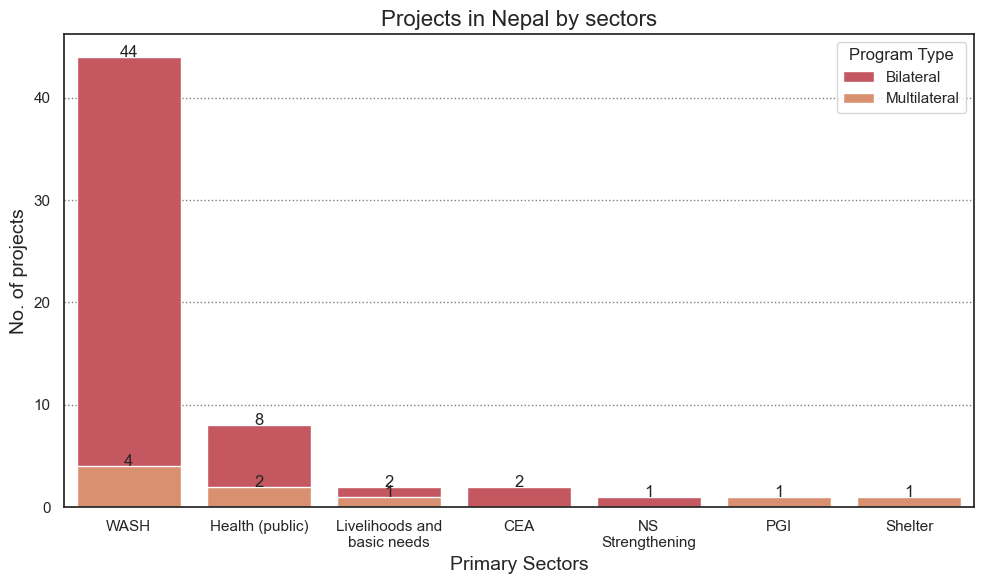
We can also change the visualization and select horizontal or vertical bar charts. We can also select stacked bar charts. In this case we can also drag another column/ field like programme_type into the legends field and visualize the projects in different sectors as per the programme type (bilateral or multilateral) (see below).
¶ Using Python
In this section, we will show how the data can be received from the Project API endpoint using python. Using the country parameter we will retrieve the Projects data for Nepal. We will be using Jupyter notebooks to implement the python code. Jupyter notebooks is a open source tool used for interactive computing, data analysis, data visualizing and machine learning. They provide an interactive cloud base interface that allows the users to create and share documents with code, equations, visualizations and text.
To access the data in python, the following libraries have to be imported.
requests:For sending the HTTP request to the API endpoint.collections:Provides specialized container data types that are alternatives to the built in data types like lists, tuples and dictionaries. These data types are more efficient and come with additional methods making your code more readable.matplotlib.pyplot:Used for creating static and animated visuals in python.numpy:Used for handling large and multidimensional arrays, thus facilitating data analysis.
import requests
from collections import Counter
import matplotlib.pyplot as plt
import numpy as npNow we will define a helper function named fetchProjects to query the API endpoint using requests library to retrieve a list of projects from a specific country. It construct a specific API requests with the specified country name, pagination parameters, and an authorization token. The function continues to make API requests until all the projects from the specified country have been retrieved. The fetched projects are accumulated in a list called all_results and then returned as a final output of the function.
def fetchProjects(country):
base_url = "https://goadmin.ifrc.org/api/v2/project/"
offset = 0
page_size = 50
all_results = []
auth_token = "Your authorization token"
while True:
params = {
"country": country,
"offset": offset,
"limit": page_size
}
headers = {
"Authorization": f"Bearer {auth_token}"
# Add other headers if needed
}
response = requests.get(base_url, params=params, headers=headers)
data = response.json()
projects = data.get("results", [])
if not projects:
# No more results, break the loop
break
# Add fetched projects to the results list
all_results.extend(projects)
# Increment offset for the next page
offset += page_size
return all_resultsNext we define another function named getDataFromProjects which takes a list of projects as an input. This function is used for processing the output of the previous function fetchProjects which gives list of number of projects in a country. Then each of these projects are processed to count the frequencies of primary sectors and program types. It then sorts the primary sectors by the number of projects in descending order. Finally it returns the frequency of sorted primary sectors and count of projects by program type.
def getDataFromProjects(projects):
primary_sector_counter = Counter()
sector_programme_counter = Counter()
for project in projects:
# Count projects by primary sector
primary_sector = project['primary_sector_display']
primary_sector_counter[primary_sector] += 1
programme_type = project['programme_type_display']
sector_programme_counter[programme_type] +=1
# Sort primary sectors by count in descending order
sorted_primary_sectors = dict(sorted(primary_sector_counter.items(), key=lambda x: x[1], reverse=True))
return sorted_primary_sectors, sector_programme_counterNext we define two more functions named textwrap and plotPrimarySectors for plotting barcharts to display the number of projects in Nepal by primary sector. The textwrap function is used the wrap the x axis labels on the plot which are the names of primary sectors in the data. We also display the count of projects by primary sectors in Nepal above each bar in the plot.
import textwrap
def wrap_labels(labels, width=15):
wrapped_labels = [textwrap.fill(label, width) for label in labels]
return wrapped_labels
def plotPrimarySectors(primary_sectors_data):
labels, values = zip(*primary_sectors_data.items())
wrapped_labels = wrap_labels(labels)
custom_colors = ['#0d6abf', '#73361c', '#eb895f', '#893395', '#d64550', '#73361c', '#f0e199']
plt.figure(figsize=(10,6))
plt.bar(range(len(wrapped_labels)), values, color=custom_colors, align='center')
for index, value in enumerate(values):
plt.text(index, value + 0.05, str(value), ha='center', va='bottom', fontsize=10) # Display data labels on top of bars
plt.xlabel('Primary Sectors', fontsize=14)
plt.xticks(range(len(wrapped_labels)), wrapped_labels, rotation=0, ha='center', fontsize=11) # Wrap and set x-tick labels
plt.yticks(fontsize=12)
plt.ylabel('Number of Projects', fontsize=14)
plt.title('Projects in Nepal by Sectors', fontsize=16)
plt.tight_layout()
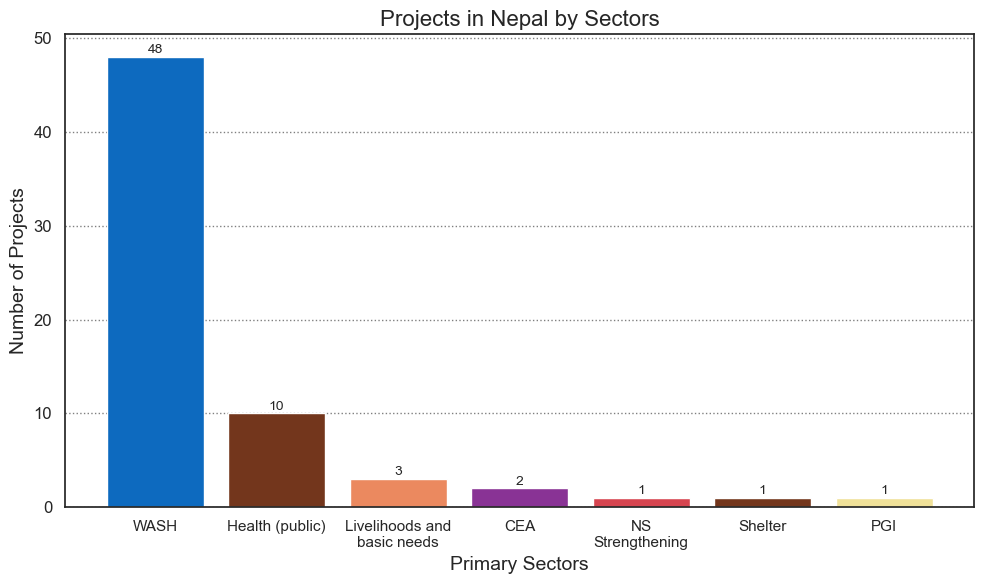
plt.show()The code below is used to call the functions defined before. In summary, the code below fetches a list of projects in Nepal. Then the list of projects obtained are processed using the getDataFromProjects function and the output is used to plot the distribution of projects across different primary sectors in Nepal using the plotPrimarySectors function. The sequence of steps allows for the retreieval, analysis and visualization of projects data specific to Nepal from the IFRC API.
projects = fetchProjects("NPL")
sorted_primary_sectors = getDataFromProjects(projects)[0]
programme_type = getDataFromProjects(projects)[1]
plotPrimarySectors(sorted_primary_sectors)
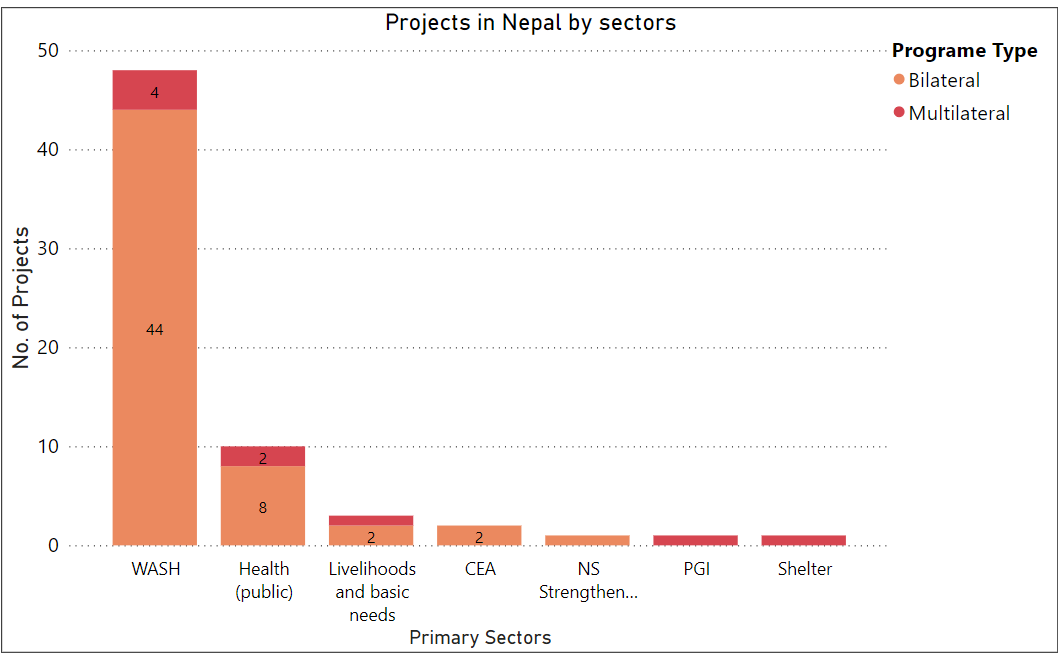
Next, we plot a grouped barchart to show the number of projects in Nepal by primary sector and program type. The function named projects_data_frames takes a list of projects as an input and creates a Dataframe with “Primary_sector_display” and "programme_type_display" as columns. It iterates through all the projects and extracts the specified columns, creates a dictionary for each project with the selected data and appends these dictionaries into a list. Finally this list of these dictionaries into pandas DataFrame and returns it as the output.
def projects_dataframe(all_results):
selected_columns = ["primary_sector_display", "programme_type_display"]
projects_data = []
for project in all_results:
selected_data = {key: project.get(key, None) for key in selected_columns}
projects_data.append(selected_data)
return pd.DataFrame(projects_data)
df = projects_dataframe(projects)For plotting we will be using another library called seaborn which makes it easier to plot grouped barcharts.
grouped_dfcontains counts of projects for each unique combination of 'primary_sector_display' and 'programme_type_display'.sorted_dfsums up the counts of projects for each primary sector and sorts them in descending order based on the total count.
We plot a grouped barchart using the sns.barplot function and then later on specify the X and Y axis labels along with the legend showing the program type.
import seaborn as sns
grouped_df = df.groupby(['primary_sector_display', 'programme_type_display']).size().reset_index(name='count')
sorted_df = grouped_df.groupby('primary_sector_display')['count'].sum().reset_index().sort_values(by='count', ascending=False)
custom_palette = [ "#d64550", "#eb895f"]
# Plot
plt.figure(figsize=(10, 6))
sns.set(style="white")
sns.barplot(x='primary_sector_display', y='count', hue='programme_type_display',
data=grouped_df, palette=custom_palette,
dodge=False, order=sorted_df['primary_sector_display'])
# Wrap x tick labels
tick_labels = list(sorted_df['primary_sector_display'])
wrapped_labels = [textwrap.fill(label, width=15) for label in tick_labels]
plt.legend(loc='upper right', title='Program Type')
plt.xticks(tick_labels, wrapped_labels)
plt.xlabel("Primary Sectors", fontsize=14)
plt.ylabel("No. of projects", fontsize=14)
plt.title("Projects in Nepal by sectors", fontsize=16)
plt.tight_layout()
plt.show()